Replicate PostreSQL data to Elasticsearch via Logical replication slots
Why?
We all seen synchronization of data between MySQL and Elasticsearch via Kafka but there isn’t any efficient service to do it with Postgres in mind to minimize impact on production stack. Many production enviroments contain databases over 1 Terabyte data with high load and we don’t wan’t to increase load on the system why adding additional queries. There was the part I tought about is there a way I can use that’s native to Postgres but needs to be compatible with master-master clustering and single instance. Ok only mature master-master replication system is Postres-BDR and it uses logical replication lets extend it’s purpuse.
What?
So in this post, we’ll describe how to replicate data from PostgreSQL to Elasticsearch with Logical replications slots with no data lost and near real-time. We aren’t going to explain or disscus following technology but we mention it:
Use case
Often relation based database systems are to slow for big queries with joins, analytics or audit but we want to keep the data integrity. One solution is to mix relational database management system (RDMS) with noSQL storage like ELK stack for fast lookups and Kibana visualizations. So we want:
- Data to be synchronized to RDMS as much as possible
- Mirror all changes in real-time to noSQL storage
- Scale with clusters
- Atomic level of control what gets synchronized
To solve this problem we’ll use PostgreSQLs replication slots with Logical Decoding to replicate data to Elasticseach.
Logical and physical replication slots
Standard replication in PostgreSQL is physical replication. The disk files that exist on the standby are essentially byte-for-byte identical to the ones on the master. When a change is made on the master, the write-ahead log is streamed to the standby, which makes the same change to the corresponding disk block on the standby. The alternative is logical replication, in which what is transferred is not an instruction to write a certain sequence of bytes at a certain location, but the information about data manipulation language (DML) or table that was created within given schema.
Physical replication has some of serious disadvantages:
- Can’t replication to a different major version of PostgreSQL
- Can’t replicate to a database other than PostgreSQL
- Can’t replicate part of the database
- Can’t write any data at all on the standby
Logical replication sends only row changes and only for committed transactions, and it doesn’t have to send vacuum data, index changes, etc. It can selectively send data only for some tables within a database. This makes logical replication much more bandwidth efficient. So we can replicate only what we want to.
All PostgreSQL versions >= 9.4 are supported.
Main advantage is that Logical replication has plugin system that can be used as pipeline to other database systems as it’s an easy to understand protocol. More about logical replication slots
Logical decoding
Logical decoding is the process of extracting all persistent changes to a database’s tables into a coherent, easy to understand format which can be interpreted without detailed knowledge of the database’s internal state. So Logical decoding works on top of replication slots and decoding plugins which send DML changes on DB and make them understandable to external clients. Replication slot represents stream of changes on one database.
Each change is decoded row by row even if they are produced in one command or transaction.
Note: Unlogged and temp tables are not decoded.
Features:
- Flexible storage through replicating smaller sets (even partitioned tables)
- Minimum server load compared with trigger based solutions
- Data transformation
- Flexible output due to plugins
- Persist across crashes and know nothing about the state of their consumer(s).
Note:
Replication slots will prevent removal of required resources even when there is no connection using them. This consumes storage because neither required WAL nor required rows from the system catalogs can be removed by VACUUM as long as they are required by a replication slot. So if a slot is no longer required it should be dropped.
Solution and it’s architecture
Solution parts:
- Replication slot on database
- wal2json output plugin to decode changes in json
- Integration service pg-replicate-elastic self developed to make json Elasticsearch frendly and filter out tables/columns that we don’t want to replicate
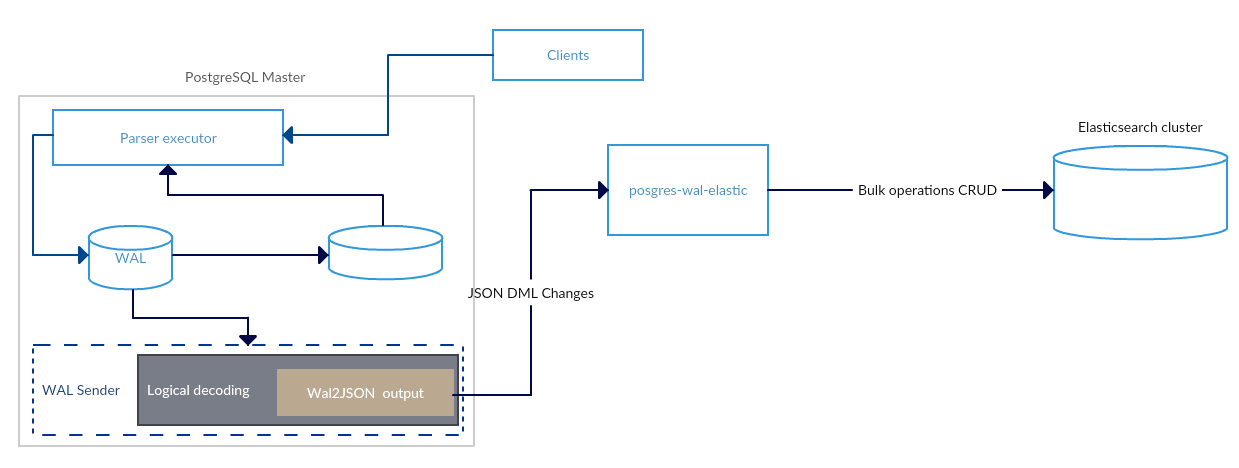
Data flow goes from SQL DML to Logical replication slot that decodes the changes into json via wal2json and sends it out to integration service pg-replicate-elastic that uses multiple threads to applay changes into Elasticsearch. Each table will represent new index in Elasticsearch with same name.
Next we go to techinal part of this post.
PostgreSQL manage replication slots
Configuration
Minimum postgresql.conf configuration:
wal_level = logical # Replication type
max_replication_slots = 1 # Maximum number of replication slots, must be at least 1
max_wal_senders = 10 # max number of walsender processes
wal_keep_segments = 4 # in logfile segments, 16MB each; 0 disables
#wal_sender_timeout = 60s # in milliseconds; 0 disables
Minimum pg_hba.conf configuration:
local replication <your_replication_user> trust
host replication <your_replication_user> 127.0.0.1/32 trust
host replication <your_replication_user> ::1/128 trust
Note: User that we use to connect to DB must have at least replication permissions.
Some output plugins
- Json output (this one we used in this post) wal2json
- Google Protocol Buffers output postgres-decoderbufs
SQL management
Example management with wal2json (all is the same with others) plugin:
SELECT * FROM pg_create_logical_replication_slot('example_slot', 'wal2json'); -- Creates replication slot with name and output plugin
SELECT * FROM pg_logical_slot_get_changes('example_slot', NULL, NULL); -- Returns changes in the slot example_slot, starting from the point at which since changes have been consumed last
SELECT * FROM pg_logical_slot_peek_changes('example_slot', NULL, NULL); -- Behaves just like the pg_logical_slot_get_changes() function, except that changes are not consumed; that is, they will be returned again on future calls
SELECT pg_drop_replication_slot('example_slot'); -- Drops replication slot by name
For more detail look at System Administration Functions
PostgreSQL built-in tools:
pg_recvlogical controls logical decoding replication slots and streams data from such replication slots:
$ pg_recvlogical -d postgres --slot example_slot --create-slot -P wal2json
$ pg_recvlogical -d postgres --slot example_slot --start -o pretty-print=1 -o write-in-chunks=0 -f -
$ pg_recvlogical --help
Tuning Elasticsearch for performance and our use case
Bulk requests with multiple threads sending data
Bulk requests will yield much better performance than single-document index requests so we explicit use bult requests in chunks of 20 with multithreading. Only 20 because when large transactions acure in PostgreSQL we don’t want to make memory pressure when many of them are sent concurrently. This is implementend ing pg-replicate-elastic.
Refresh interval
As we need to load a large amount of data at once (multiple bulks of 20 at 1 second), you should know your average database operations per second and set it by setting index.refresh_interval to your needs. Some exaple data:
refresh_interval: 1s ~ 2.0K ops
refresh_interval: 5s ~ 2.5K ops
refresh_interval: 30s ~ 3.4K ops
If you disable it total (set it to -1) lets say at initial syncronization there is a potencial risk as lost of any shard will result in data lost. It’s one to do this in an short inital process but not in production and larger period of time.
Disable swap
Elasticsearch runs on Java so don’t allow it to use swap.
Linux systems disable swap temporarily:
$ sudo swapoff -a
To disable swap permanently comment out all lines in ` /etc/fstab ` that have have word ` swap ` in it.
pg-replicate-elastic service
pg-replicate-elastic is our service tool that implements blog posts solution.
Features:
- Autocreate indexes with same names as database tables
- Consume wal2json output
- Replicate data to Elastic in chunks of 20 with multithreaded requests
- Filter out tables what we want to replicate
- Exclude table columns
Installing pg-replicate-elastic
Prerequisites: Python 2.7, Elasticsearch >= 5.0, PostgreSQL >= v9.4
Install pg-replicate-elastic from PyPi:
$ pip install pg-replicate-elastic
Construct configuration file in json format where:
- replication_slot json object for replication slot name and if is temporary
- tables is array of tables we want to replicate
- es_connection connection string to Elasticsearch
- postgres json object for PostreSQL connection
- inital_sync boolean for inital syncronization that needs to be done first time to replicate old data
Example configuration
{
"replication_slot": {
"name": "elasticsearch_slot",
"is_temp": true
},
"tables": [{
"name": "poc",
"primary_key": "a"
"exclude_columns": "c"
}],
"es_connection": "http://127.0.0.1:9200/",
"postgres": {
"port": 5432,
"host": "127.0.0.1",
"database": "poc",
"username": "test",
"password": "test"
},
"inital_sync": false
}
Usage
pg_replicate_elastic --config=<absolute path to json config>
Clustering and high availability
On the Elasticsearch side there are no problems as we don’t need to handle replication logs, just one Haproxy infront of it and we are good to go.
Haproxy configuration for elasticsearch:
listen elasticsearch
bind *:9200
balance roundrobin
mode tcp
timeout client 400s
timeout server 400s
server elasticsearch-1 10.5.0.1:9200 check inter 10000 rise 3 fall 3
server elasticsearch-2 10.5.0.2:9200 check inter 10000 rise 3 fall 3
For PostreSQL we use Postres-BDR cluster Master-Master asynchronous replication or synchronous master-slave. The problem is that most production PostgreSQL deployments rely on streaming replication and/or WAL archive based replication (“physical replication”) and the replication slots are not replicated to other nodes in the cluster.
Now you thing to just create slots on other nodes, yes but we need to be sure to consume slots on both nodes and take care that we inital replicate the node with the oldest data that implemented with inital_sync in pg-replicate-elastic. This aprouch take twice bandwidth and spams Elasticsearch with duplicate CRUD even we handle this situation.
An better solution is that we have just one temporary replication slot and many rendundant pg-replicate-elastic instances so if any error accures or node fails the slot is drop automatic. To prevent pg-replicate-elastic clients to connect to random nodes we use HAProys balance mode first so that allways the first healthy node is used.
Haproxy configuration for HA replication slots:
listen postgres-bdr-cluster
bind *:5432
balance first
mode tcp
timeout client 400s
timeout server 400s
default-server maxconn 1000
option pgsql-check user snaga
server postgres1 10.5.0.1:5432 check inter 10000
server postgres2 10.5.0.2:5432 check inter 10000
server postgres3 10.5.0.3:5432 check inter 10000
Demo
Similar services and tools
- ZomboDB - Postgres extension that enables efficient full-text searching via the use of indexes backed by Elasticsearch.
- Transporter - Sync data between persistence engines, like ETL only not stodgy
For our use case this solution don’t offer some features like complete CRUD synchronization or control like specific tables and exclude columns.
References:
- https://www.postgresql.org/docs/10/static/
- http://paquier.xyz/postgresql-2/postgres-10-temporary-slot/
- https://blog.2ndquadrant.com/logical-replication-postgresql-10/
- https://blog.2ndquadrant.com/logical-replication-postgresql-10/
- https://www.slideshare.net/8kdata/postgresql-logical-decoding
- https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
QA
For any questions don’t hesitate to ask in comment below :)